Deploying IBM Watson NLP to OpenShift using KServe Modelmesh

In this blog, I will demonstrate how to deploy the Watson for NLP Library to OpenShift using KServe Modelmesh.
For initial context, read my blog introducing IBM Watson for Embed.
For deployment to Kubernetes, see this blog.
Introducing KServe
KServe is a standard model inference platform on k8s. It is built for highly scalable use cases and supports existing third party model servers and standard ML/DL model formats, or it can be extended to support additional runtimes like the Watson NLP runtime.
Modelmesh Serving is intended to further increase KServe’s scalability, especially when there are a large number of models which change frequently. It intelligently loads and unloads models into memory from from cloud object storage (COS), to strike a trade-off between responsiveness to users and computational footprint.
Install Kserve Modelmesh on OpenShift
KServe Modelmesh requires etcd, S3 storage and optionally Knative and Istio.
Two approaches are available for installation:
- A quick start approach which includes all the pre-reqs, i.e. etcd and even local cloud object storage (COS) with minIO.
- A customizable approach which requires Etcd to be already installed.
I took the quick start approach and installed to an OpenShift cluster with the following commands:
1
2
3
4
RELEASE=release-0.9
git clone -b $RELEASE --depth 1 --single-branch https://github.com/kserve/modelmesh-serving.git
cd modelmesh-serving
oc new-project modelmesh-serving
The quickstart at release-0.9 currently has limitations meaning the etcd and Minio pods will crash at startup on OpenShift (although it works fine on Kubernetes). This can be resolved by editing the etcd and minio Deployments in /config/dependencies/quickstart.yaml
For etcd, specify an alternative --data-dir shown in the last two lines below:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: etcd
name: etcd
spec:
replicas: 1
selector:
matchLabels:
app: etcd
template:
metadata:
labels:
app: etcd
spec:
containers:
- command:
- etcd
- --listen-client-urls
- http://0.0.0.0:2379
- --advertise-client-urls
- http://0.0.0.0:2379
- --data-dir
- /tmp/etcd.data
For minio, change the -data1 to -/tmp/data1 as shown in the last line below:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: minio
name: minio
spec:
replicas: 1
selector:
matchLabels:
app: minio
template:
metadata:
labels:
app: minio
spec:
containers:
- args:
- server
- /tmp/data1
Now run the quickstart script:
1
./scripts/install.sh --namespace modelmesh-serving --quickstart
After the script completes, you will find these pods running:
1
2
3
4
5
6
oc get pods
NAME READY STATUS RESTARTS AGE
etcd 1/1 Running 0 76m
minio 1/1 Running 0 76m
modelmesh-controller-77b8bf999c-2knhf 1/1 Running 0 75m
By default, there are some default serving runtimes defined:
1
2
3
4
5
6
oc get servingruntimes
NAME DISABLED MODELTYPE CONTAINERS AGE
mlserver-0.x sklearn mlserver 4m11s
ovms-1.x openvino_ir ovms 4m11s
triton-2.x keras triton 4m11s
Create Cloud Object Storage Bucket
The installation created a secret with credentials for the local minIO object storage.
1
2
3
4
oc get secret/storage-config
NAME TYPE DATA AGE
storage-config Opaque 1 117m
The secret contains connection details for the “localMinIO” COS endpoint. This secret becomes important later when uploading the models to be served. The secret also defines the default bucket of modelmesh-example-models, which needs to be created on mino. This can either be achieved using the mc cli, or you can access the minio GUI for this simple task:
1
oc port-forward service/minio 9000:9000
Open localhost:9000 in a browser. Login using the credentials in the secret which you can view either via the OpenShift console or cli:
1
oc get secret/storage-config -oyaml
For example:
1
2
3
4
5
6
7
8
{
"type": "s3",
"access_key_id": "XXXXX",
"secret_access_key": "XXXXX",
"endpoint_url": "http://minio:9000",
"default_bucket": "modelmesh-example-models",
"region": "us-south"
}
In the minio GUI, click the red ‘+’ button (located bottom right) to add a bucket named modelmesh-example-models
Creating this bucket is a workaround and is not required when using the quick start install script with Kubernetes. The minio container deployed by the quick start includes a default directory /data1, which is pre-populated with a bucket modelmesh-example-models containing some default models for pytorch, sklearn, tensorflow etc.
Because OpenShift containers do not run as root, the minio container cannot write to /data1, hence in a previous step we instead configured minio to use /tmp/data1, to which the non-root user will have write access. However, /tmp/data1 does not include the bucket modelmesh-example-models, hence the additional steps above to create it. Also, if you wanted to make use of the default models in /data1, you would also need to move these files into /tmp/data1.
Create a Pull Secret and ServiceAccount
Ensure you have a trial key.
1
2
IBM_ENTITLEMENT_KEY=<your trial key>
oc create secret docker-registry ibm-entitlement-key --docker-server=cp.icr.io/cp --docker-username=cp --docker-password=$IBM_ENTITLEMENT_KEY
An example ServiceAccount is provided. Create a ServiceAccount that references the pull secret.
1
2
git clone https://github.com/deleeuwblue/watson-embed-demos.git
oc apply -f watson-embed-demos/nlp/modelmesh-serving/serviceaccount.yaml
Configure Modelmesh Serving to use this ServiceAccount, giving the controller access to the IBM entitled registry. Use the OpenShift console to edit the Workloads->ConfigMap model-serving-config-defaults in the modelmesh-serving namespace.
Set serviceAccountName to pull-secret-sa. Also disable restProxy as this is not supported by Watson NLP:
1
2
3
4
5
6
7
8
9
10
apiVersion: v1
kind: ConfigMap
metadata:
name: model-serving-config
data:
config.yaml: |
#Sample config overrides
serviceAccountName: pull-secret-sa
restProxy:
enabled: false
Restart the modelmesh-controller pod:
1
2
oc scale deployment/modelmesh-controller --replicas=0 --all
oc scale deployment/modelmesh-controller --replicas=1 --all
Configure a ServingRuntime for Watson NLP
An example ServingRuntime resource is provided. The serving runtime defines the cp.icr.io/cp/ai/watson-nlp-runtime container image should be used to serve models that specify watson-nlp as their model format. Note that ServingRuntime recommended by the official documentation includes resource limits. Because I was testing with a small OpenShift cluster, I needed to comment these out.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
apiVersion: serving.kserve.io/v1alpha1
kind: ServingRuntime
metadata:
name: watson-nlp-runtime
spec:
containers:
- env:
- name: ACCEPT_LICENSE
value: "true"
- name: LOG_LEVEL
value: info
- name: CAPACITY
value: "6000000000"
- name: DEFAULT_MODEL_SIZE
value: "500000000"
- name: METRICS_PORT
value: "2113"
args:
- --
- python3
- -m
- watson_runtime.grpc_server
image: cp.icr.io/cp/ai/watson-nlp-runtime:1.0.20
imagePullPolicy: IfNotPresent
name: watson-nlp-runtime
# resources:
# limits:
# cpu: 2
# memory: 8Gi
# requests:
# cpu: 1
# memory: 8Gi
grpcDataEndpoint: port:8085
grpcEndpoint: port:8085
multiModel: true
storageHelper:
disabled: false
supportedModelFormats:
- autoSelect: true
name: watson-nlp
Create the ServingRuntime resource:
1
oc apply -f watson-embed-demos/nlp/modelmesh-serving/servingruntime.yaml
Now you see the new watson NLP serving runtime, in addition to those provided by default:
1
2
3
4
5
6
7
oc get servingruntimes
NAME DISABLED MODELTYPE CONTAINERS AGE
mlserver-0.x sklearn mlserver 7m6s
ovms-1.x openvino_ir ovms 7m6s
triton-2.x keras triton 7m6s
watson-nlp-runtime watson-nlp watson-nlp-runtime 7s
Upload a pretrained Watson NLP model to Cloud Object Storage
The next step is to upload a model to object storage. Watson NLP provides pre-trained models as containers, which are usually run as init containers to copy their data to a volume shared with the watson-nlp-runtime, see [Deployments to Kubernetes using yaml files or helm charts]. When using Modelmesh, the goal is to copy the model data to COS. To achieve this, we can run the model container as a k8s Job, where the model container is configured to write to COS instead of a local volume mount.
An example Job is provided which launches the model container for the Syntax model. The env variables which configure the model container to copy its data to COS, referencing the credentials from the localMinIO section of the storage-config secret, which is mounted as a volume.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
apiVersion: batch/v1
kind: Job
metadata:
name: model-upload
namespace: modelmesh-serving
spec:
template:
spec:
containers:
- name: syntax-izumo-en-stock
image: cp.icr.io/cp/ai/watson-nlp_syntax_izumo_lang_en_stock:1.0.7
env:
- name: UPLOAD
value: "true"
- name: ACCEPT_LICENSE
value: "true"
- name: S3_CONFIG_FILE
value: /storage-config/localMinIO
- name: UPLOAD_PATH
value: models
volumeMounts:
- mountPath: /storage-config
name: storage-config
readOnly: true
volumes:
- name: storage-config
secret:
defaultMode: 420
secretName: storage-config
restartPolicy: Never
backoffLimit: 2
Create the Job:
1
oc apply -f watson-embed-demos/nlp/modelmesh-serving/job.yaml
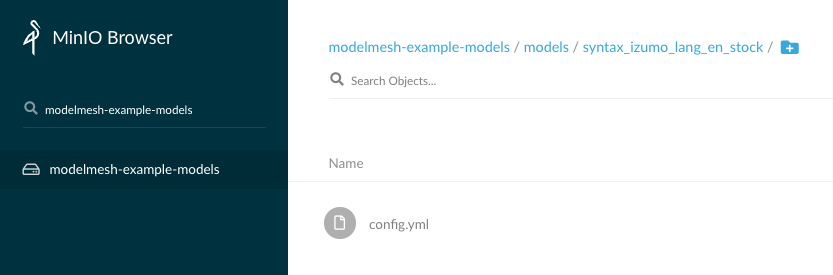
The minio GUI shows the uploaded model data:
Create a InferenceService for the Syntax model
Finally, an InferenceService CR needs to be created to make the model available via the watson-nlp Serving Runtime that we already created. This resource defines the location for model syntax-izumo-en in COS. It also specifies a modelFormat of watson-nlp which will associate the model with the watson-nlp-runtime serving runtime.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: syntax-izumo-en
namespace: modelmesh-serving
annotations:
serving.kserve.io/deploymentMode: ModelMesh
spec:
predictor:
model:
modelFormat:
name: watson-nlp
storage:
path: models/syntax_izumo_lang_en_stock
key: localMinIO
Create the InferenceService:
1
oc apply -f watson-embed-demos/nlp/modelmesh-serving/inferenceservice.yaml
The status of the InferenceService can be verified:
1
2
3
4
oc get InferenceService
NAME URL READY PREV LATEST PREVROLLEDOUTREVISION LATESTREADYREVISION AGE
syntax-izumo-en grpc://modelmesh-serving.modelmesh-serving:8033 True
Note, the watson-nlp-runtime container can take 5-10 minutes to download. Until this has completed, the InferenceService will show a status of false.
Test the model
The modelmesh-serving Service does not expose a REST port, only GRPC. Interacting with GRPC requires the proto files. They are published here. Enter the following commands to test the Syntax model using grpcurl:
1
oc port-forward service/modelmesh-serving 8033:8033
Open a second terminal and run commands:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
git clone https://github.com/IBM/ibm-watson-embed-clients
cd ibm-watson-embed-clients/watson_nlp/protos
grpcurl -plaintext -proto ./common-service.proto \
-H 'mm-vmodel-id: syntax-izumo-en' \
-d '
{
"parsers": [
"TOKEN"
],
"rawDocument": {
"text": "This is a test."
}
}
' \
127.0.0.1:8033 watson.runtime.nlp.v1.NlpService.SyntaxPredict
The GRPC call is routed by the modelmesh-serving Service to the appropriate serving runtime pod for the model requested. Modelmesh ensures there are enough Serving Runtime pods to meet demand. The response from the watson-nlp-runtime should look like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
{
"text": "This is a test.",
"producerId": {
"name": "Izumo Text Processing",
"version": "0.0.1"
},
"tokens": [
{
"span": {
"end": 4,
"text": "This"
}
},
{
"span": {
"begin": 5,
"end": 7,
"text": "is"
}
},
{
"span": {
"begin": 8,
"end": 9,
"text": "a"
}
},
{
"span": {
"begin": 10,
"end": 14,
"text": "test"
}
},
{
"span": {
"begin": 14,
"end": 15,
"text": "."
}
}
],
"sentences": [
{
"span": {
"end": 15,
"text": "This is a test."
}
}
],
"paragraphs": [
{
"span": {
"end": 15,
"text": "This is a test."
}
}
]
}